A Peek into Text Mining: How to Collect Text Data from Twitter
In the last 25 years, the Internet has fundamentally changed the way we interact with each other. In 1993 there were only 50 static pages on the World Wide Web. Today, social networking tools alone have billions of active users.
Communication through social networking tools is both bidirectional and many-to-many at the same time. We can keep contact with our friends, friends of friends, and any number of people with shared interests. In these networks, a piece of information can easily travel along many different paths and have unforeseen impact.
Text Mining
These changing communication patterns coincide with new frontiers for academic research. 30 years ago, text mining did not exist as an independent academic field. Text data sets were expensive, and machines were not powerful enough to store or sort large amounts of text information. Today, researchers in the broad area of natural language processing list text analysis as one of the most important research areas. Text analysis is not only a challenging problem, but also a powerful tool that has been employed in diverse fields such as business, humanities and health sciences. Education is not an exception. Online activities are increasingly integrated into classroom learning, more and more people are using open educational resources and students worldwide connect through online learning communities. The resulting communication streams offer a vast amount of material for analysis.
Anyone Can Explore Big Data
Despite the potential, many educational researchers are unaware about how relatively easy it is to collect big data from social networking sites and how to process it. This post offers a basic introduction to educational researchers interested in text analysis on social networking tools and focuses on data collection from Twitter. Though data from Twitter is not fundamentally different from data from other social media networks, Twitter has unique characteristics that make it particularly interesting for text mining. On the one hand, weak-tie connection among people on Twitter is stronger than other networks, which greatly increases information exposure. On the other hand, Twitter has word limits on each tweet. Users tend to use precise rather than artful language when faced with this limit, which makes connections more obvious. To collect my data set, I am using R, an open source language and environment for statistical analysis. The following step-by-step instructions enable you to collect your own data set.
Download and Start Using R
If you are using Mac, please go to http://www.r-project.org/, click “download R” and follow the rest of the steps until you finish the installation. If you are using Windows, you may want to download R-studio when you finish installing R. R-studio provides a more user-friendly interface for Windows users.
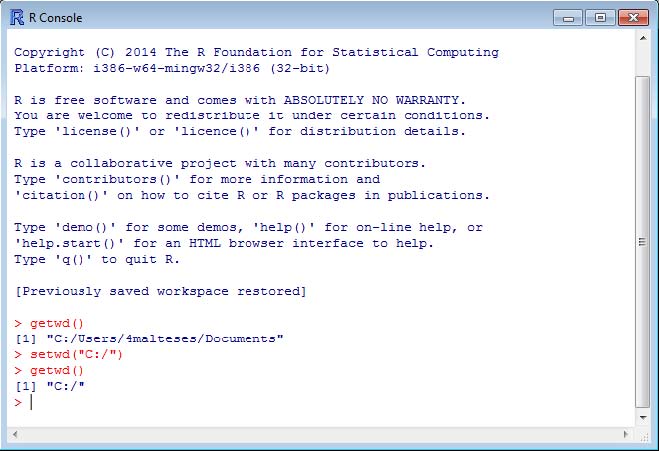
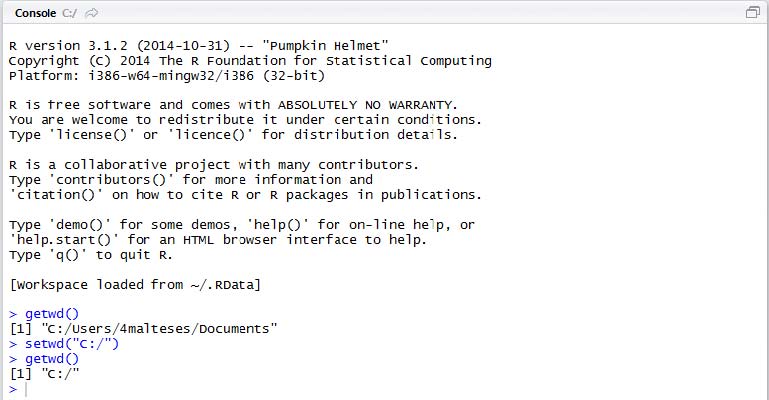
The only knowledge that you need about R for now is the concept of working directory. R is capable of reading from and writing to a specific folder of your system, and the specific folder is the working directory to R. You can use the following command to check the current working directory of R:
getwd()
To specify which directory you would like R to use as the working directory, you can use setwd() command. The following example tells R to use C:/ as the working directory.
setwd("C:/")
Data Collection Approach 1: Popular hashtags
Some Twitter hashtags are very popular, and different people around the world keep tweeting using these hashtags constantly, like #elearning or #edutech. Some other hashtags, in contrast, may not be as popular, but more relevant and meaningful to a specific community, like the hashtag for SITE conference #siteconf. For tweets with the two different types of hashtags, Twitter weighs and indexes them differently, which requires different approaches for data collection. This section discusses how to collect information for a popular hashtag, using the example #edutech.
Create a Developer Account and Application on Twitter
To collect data from Twitter, you will need a developer account on Twitter first. You can register one at https://dev.twitter.com/. Once you have a developer account, return to the page and scroll down to the bottom of the page, click “Manage Your Apps” under “Tools”.

Now, simply click on “Create New Application” button on the following new page:

On the application creation page, the only thing you need to remember is to fill the Callback URL as http://127.0.0.1:1410.
When you finish the creation step, you can check the details of your application:
The generated consumer keys and secrets would be under the tab “Keys and Access Token”. This piece of information will be important for you to successfully connect to Twitter later on.
Connection and Data Collection
If you have finished the installation of R and figured out what working directory is, then you can march ahead towards data collection by connecting to Twitter using R. One reason I love R is that it has a very active community. No matter what statistical calculation you need to do, or what common function you need to run, there’s always a package out there online. A package is a collection of R functions that make your life easier. Instead of writing your own functions for a purpose, you can instead just use the function coded by other people, in this case, a package called “twitteR” that implements Twitter’s APIs and can greatly simplify the code for connecting to Twitter. If you want to know more about the package, please check its manual here.
I am curating a collection of functions and detailed explanations on Github. If you have a Github account, please feel free to watch the progress of the functions. I am always trying to update them when there is any change in the package.
To connect to Twitter using R, simply copy and paste the codes in the file Authentication.R to your R (or R-studio) console. Please remember to replace the “xxxxx” with your own consumer keys and secrets before running the codes. When R returns the following strings, you will know that you have successfully connected to Twitter.
“Using browser based authentication”
Now you can move on to data collection using the hashtag you are interested in. Please copy and paste the codes in the file hashtagSearch.R, then run it. Type the following sample codes in the console after you run the codes in hashtagSearch.R:
tweetCollect("#statistics", 100, "statistics_from_twitter")
Now you can access your working directory and find a file named statistics_from_twitter.csv. This file contains your data. The above code simply tells R to collect 100 tweets using the following hashtag: #statistics. You can replace the hashtag with whatever you like to explore, and you can also increase or decrease the number of tweets to collect.
Data Collection Approach 2: Specific hashtags
If the tweets you would like to collect are not using constantly popular hashtag, the first thing you need to do is to search the hashtag using Twitter’s search function. If we would like to, for example, collect most tweets about SITE conference in recent two years using the hashtag “#siteconf”, we can just search the hashtag:

Only most recent data is shown on this page, because Twitter is implementing infinite scrolling. What you need to do is to keep scrolling the page until all the tweets in recent two years show up on one page, and then you can save the HTML page to the working directory of R.
Data Processing
Technically speaking, the data collection is already finished. However, you still have to process the data before it can be used for future analysis. The goal is to format the tweets in two columns. One column represents the original tweets, while the other represents the processed tweets without the hashtag and hyperlinks. Each row represents tweets from an individual.
To process the data, copy and paste the codes in the file parse_Tweets_simplified.R, then run it in R. After that, type the following sample codes in the console:
getData("#siteconf", "#siteconf - Twitter Search.html", "siteconf_from_twitter.csv")
Now go to your current working directory and find a file named siteconf_from_twitter.csv, and that’s your data. The above code simply tells R to parse the tweets in the HTML file into your specified csv file. You can replace the hashtag with whatever you like to explore, and repeat all the above steps in this section.
What next?
This is a series of two postings on text mining. Watch for my next post on how to conduct data visualization and further analysis. If you are interested in learning more about R, this is a list of recommended books.
